How to Get Started Building Bespoke CI/CD Pipelines
While planning lays the groundwork, orchestration breathes life. It is up to you to determine what tool and strategy to include in your CI/CD pipeline to produce a bespoke, unique solution.

Many greenhorn DevOps engineers believe that true CI/CD maturity required a Kubernetes cluster, everything had to be a micro-service, deployments could only be blue/green, and a five-nine high availability was an absolute must.
Honestly? They’re not entirely wrong. Many of those architectural decisions and implementations are a pipe dream to many DevOps engineers, and some already have them implemented, even in their own home labs! Fret not, if you have automated even the tiniest bit of your build and deployment process with scripts, congrats, you have a CI/CD pipeline, starting your journey along the CI/CD maturity model.
Designing a bespoke CI/CD solution
When designing a CI/CD workflow, there are a couple of key considerations that must be accounted for to maintain the best flexibility for your organization or project.
For Scalability and Availability, ask:
- Do I need high availability?
- How quickly do deployments occur?
- How seamless should rollbacks be, if needed?
For Cost and Tooling, ask:
- Do I have the budget for paid solutions, or must it be free or a combination?
- Do I need enterprise support?
For Flexibility and Portability, ask:
- How "portable" is my workflow?
- How do dependencies look like? Are they internal or external? Are there chained builds or dependencies required?
- Have I considered how modular my current CI/CD setup is? What's critical and what can be simplified?
For Source Control and Testing, ask:
- How frequent do I want to test?
- Do I want to include static code analysis or security scanning?
- How can I align cadences with releases?
If high availability is critical, you might prioritize tools with strong support for distributed runners, such as GitLab CI or CloudBees. For portability, consider setting up your CI/CD in a way that leverages containerized runners. Conversely, opting for simplicity over high availability may give you the opportunity to save costs and complexity.
Portability often comes from modularizing pieces of, or the entire build process. For example, containerizing build agents can simplify a transition from on-prem builds to cloud-based solutions.
You’ll realize that answering these questions reveals some sort of trade-off. For example, achieving portability might mean sacrificing convenience. You should strongly consider taking inventory of what you currently have; you may not realize that you already leverage tools, such as GitHub, acting as an initial foundation.
Everything requires careful planning
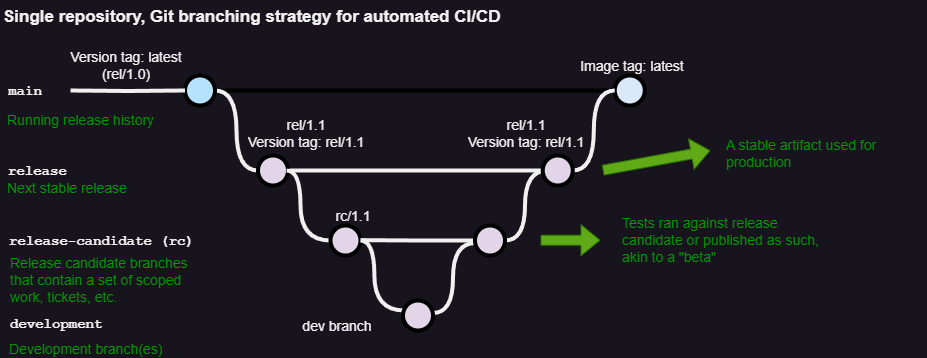
A common approach is to allocate work to dedicated, or feature specific, branches that will eventually merge back to a branch used for release and production. This doesn’t mean that there needs to be a release, release candidate, and development branch, but the main idea is to utilize branches to keep track of development work whilst ensuring stable and reproducible build artifacts.
In the home lab, this type of planning is most likely overkill, and typically can be skipped in favor of other stages in the lifecycle. In larger organizations, a leadership team that can plan, set pacing, and dole out work while keeping overall mental and development load comfortable helps immensely. This can be implemented by a few concepts:
- Introducing feature flags so normal development or production can continue without being interrupted. You can leverage tools or even an internal database to accomplish this.
- Planning the number of features, bug fixes, being implemented into the next release.
If the work planned out ends up touching a sizeable chunk of the baseline, ask yourself: - What is the priority of this work?
- If I’m going to work on something that would span multiple releases, what is my strategy for maintaining the branch to stay up to date with upstream?
- How can I break the work into more manageable chunks?
- Am I introducing too much change and updates that cross between other services?
- What work can be done in parallel?
In short, it boils down to risk vs progress: imagine merging in a half-baked feature into the baseline that gets deployed and breaks critical functionality. Could this have been avoided to begin with? Was there proper testing and burn-in time? Could feature flags have helped here?
Standardize a development environment
Once you have a clear plan, the next step is ensuring your development environment is standardized to avoid costly inconsistencies. Thorough preparation, along with a standardized set of tools, can make the development, integration, and deployment stages much easier. One common issue developers face is an ever-changing development environment that eventually drifts so much, it’s almost impossible to rely on it for a consistent experience (this is a broad generalization!). Configuration drift occurs when tools and dependencies on one developer’s machine begin to drastically differ from another, or even from production. Imagine a Python project where a developer is running Python 3.9 while another is using Python 3.10. This minor inconsistency over time may cause subtle bugs or incompatibility.
Utilizing containerization heavily “as” your development environment can help developers understand how the build process works, and what exactly is going into production. For those with limited containerization experience, getting started with Docker for Desktop, along with Windows Subsystem for Linux (WSL) is great. Gone are the days of “it works on my machine!” with containerization. Now, developers can align their local environments with production for a higher degree of integration and consistency.
A common example with Docker is utilizing multistage Docker builds. Simplified, you have a base layer, a build layer where the artifact is generated, then the production layer where Docker copies the generated asset(s) into the appropriate location within the image.
You should utilize a repository that is easily accessible to your build agent(s), such as Nexus, Artifactory, or even GitHub. An artifact repository ensures that generated outputs like JAR files or Docker images are stored in a central location and can be reliably accessed during deployment, or in part of another workflow.
Leverage branches for high CI/CD integration and automation
Depending on your intentions, you may opt to build and deploy a release candidate or test build to a testing environment, saving your release branch for use in production. Imagine three branches, one release, one release-candidate, and another as dev. Developers merge features from a set of scoped work from dev into release-candidate (rc), then release-candidate gets promoted, or merged, into the release branch when ready. A common approach is using semantic versioning (major/minor, e.g. 1.0.0). One may opt to include rc or nightly somewhere in the version tag to identify release candidates or indicate stability of a build.
Preferably, bugs would be caught in a mid-level promotion branch such as release-candidate or nightly, but there’s always the off-chance that a bug would slip past. You can make the decision to either roll back to a stable release build, fix the release-candidate or nightly build, or keep the bug in and wait to promote the fix into the next stable version. You must determine if it is more worthwhile and cost-effective to roll back or push forward at the expense of time and worst case, downtime.
Utilizing a good branching and versioning strategy will allow you, or your developers, to rapidly iterate and test, hopefully leading to more work being accomplished.
Builds should produce deterministic and repeatable results
When it comes to determining where to build, it depends on your personal or project’s priorities. If you’re willing to keep up the overhead and maintenance, perhaps you’ll run your own Jenkins or GitLab server. If you have more resources, maybe you’ll end up leveraging cloud-based resources, ranging from free GitHub and GitHub actions, to paid cloud-based options such as CloudBees.
One popular way of producing deterministic and repeatable builds is by using ephemeral build agents, like spinning up a fresh EC2 instance or Kubernetes. Ephemeral agents are like handing someone a fresh Lego kit every time you trigger a build. A fresh Lego kit ensures there are no leftover pieces or mistakes from past builds, interfering with the current. You tell them to follow the instructions precisely and to the letter. Both of you know what the result will be, because those instructions are well crafted, and both of you know that something went horribly wrong if the instructions for a cherry blossom tree result in an amalgamation of Lego horror.
If your planning is strong, it should hopefully be clear on what branch and its contents your pipeline will be automatically picking up, handing off to an available build agent, and eventually returning the built asset; or in cases the build is associated with a PR, the green light and build result. If the branching strategy above intrigues you, you’ll want to set up your CI/CD pipeline with a multibranch pipeline. This will allow you to act based on what’s occurring within your repository.
On PRs, it’s up to you to determine what is acceptable before marking something as mergeable. That could be running unit tests against a temporary merge of the pull request, watching if the Docker build step succeeds, or running static code analysis, etc. Or if you’re feeling particularly confident, you can skip checking and YOLO merge it.
Orchestration is where it pays off
This is the stage in a CI/CD pipeline where the infrastructure, development, and deployment processes come together (hopefully) harmoniously. It’s about providing a smooth transition of your built artifacts or services from development to production. Tools such as Ansible, Terraform, and Kubernetes can play the role of conductors, helping align different environments, configurations, and dependencies to run in sync. Terraform is great for provisioning infrastructure, while Ansible shines for automating configuration management across servers.
The first step in orchestration is determining the “how” and “where”. Where are your deliverables going? How do they get there? You’ll want to make a few considerations like so:
- Environment parity: Aim for as little configuration difference from development, testing, and production. Making it so configuration can be dynamically generated or retrieved from an environment file helps ensure debugging issues can be done in an environment that closely mirrors production
- Infrastructure as Code (IaC): Utilizing a tool like Terraform or OpenTofu allows you to define your infrastructure declaratively. Instead of having to navigate around manually in a cloud provider’s dashboard, you can write code that describes the infrastructure and its dependencies. The tools will go ahead and provision, as needed, what you describe. This aligns with the concept of reproducibility and easier scaling down the road.
- Parameterization and templating: This allows your orchestration logic to work across any environment. Instead of hardcoding values like endpoints or API keys, think of templates like a Swiss Army Knife – they adapt or react to any environment you’re deploying to, or to external events.
Perfection is NOT key
It’s easy to get started chasing after the most ideal pipeline. Some teams attempt to build and include every possible feature, such as end-to-end automatic deployments, an idempotent environment, or a complicated, error-proof rollback-safe deployment strategy. While all of these are good, implementing these features prematurely can lead to a very high degree of burnout, complexity, and eventually major technical debt.
Start small and focus on automating the most repetitive and error-prone tasks first. Gradually introduce more functionality over time as you stabilize, following the CI/CD Maturity Model.
Don’t Ignore the Human Element in a team
A robust CI/CD pipeline depends on team adoption. If the process is overly complex or poorly communicated, developers may end up passing on it, rendering your hard work moot. Resistance can also stem from a lack of training, documentation, or understanding of the tools involved. Make sure you:
- Involve the team in pipeline design to foster buy-in
- Keep documentation up to date and easy to follow
- Offer training sessions to leadership to bridge knowledge gaps
"Every Tool’s A Hammer"
While planning lays the groundwork, orchestration breathes life. It is up to you to determine what tool to include in your toolchain to produce a bespoke, unique solution. Regularly review your pipeline’s performance, get any applicable feedback, and identify areas for improvement.
Ready to start your pipeline? Try automating your build process with simple scripts or free CI/CD solutions like GitHub Actions. There is no one-size-fits all solution – your toolchain should reflect your team’s unique needs and goals. Start small and iterate, following the CI/CD Maturity Model. Whether you’re building on Kubernetes or just starting off with simple scripts, CI/CD maturity is a journey. Every tool’s a hammer, but it’s the craftsman that makes it work.



